// min 求两个int的最小值 funcmin(a, b int)int { if a < b { return a } return b }
// longestPalindrome 主要函数 funclongestPalindrome(s string)string { var buf bytes.Buffer // 用来拼接字符串的buffer // predo for i := 0; i < len(s); i++ { buf.WriteByte('#') buf.WriteByte(byte(s[i])) } buf.WriteByte('#') // 给字符串每一个字符之间加一个#,例如: // abcbac,--> #a#b#c#b#a#c# // 这样做的好处是,无论原来的字符串是奇数串还是偶数串, // 都可以格式化为奇数串,这样s.center就不会是一个 // 的间隙
format := buf.String() p := make([]int, len(format)) center, mx := 0, 0 for i := 1; i < len(format); i++ { if i < mx { p[i] = min(mx-i, p[2*center-i]) } else { p[i] = 1 } for i-p[i] >= 0 && i+p[i] < len(format) && format[i+p[i]] == format[i-p[i]] { p[i] += 1 } if mx-center < p[i] { mx = i + p[i] center = i } }
var resBuf bytes.Buffer st := center - (p[center] - 1) for i := st; i < p[center]+center; i++ { if format[i] != '#' { resBuf.WriteByte(format[i]) } } return resBuf.String() }
实现步骤
预处理:转换为奇字符串
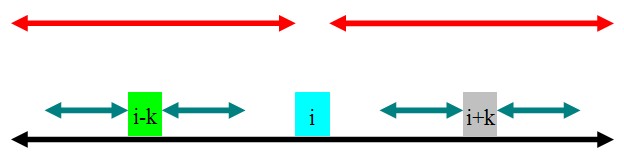
对字符串$S$,利用#填充字符之间的空隙,以达到将其转换为奇数串的目的。这样的好处是,任意下标的字符串都是一个奇数串,中心是可以由下标确定的,而不是像abba这样,中心在间隙中。 证明:任意串s,设 l = s.length(),那包括两端,l的间隙包含l+1个空位。那么,填充之后的字符串$S’$就包含$2l+1$个字符,是一个奇串。即使存在偶数回文串,那也可以以#为中心向两端扩张搜索。 e.g.:
1 2 3 4 5 6 7 8
s = "abcdcbac" s1 = "#a#b#c#d#c#b#a#c#" // center == s1[7] == 'd'
s = "abbac" s1 = "#a#b#b#a#c#" // center == s1[4] == '#'